
Web scraping is the process of extracting meaningful data from websites. Web Scraping serves as an effective way in cases where data cannot be accessed directly.
Let’s take an example to understand the concept of Web scraping with PHP; by creating a web scraping script.
In this example, a simple scraping script will be used to scrape the book data from books.toscrape.com. The data, we will scrape from the page will be the following:
- Book cover image URL (image_url)
- Book title (title)
- Price (price)
- Availability (availability)
- Book details page link (details_link)
The script will only scrape data from the home page (ie. a single URL with multiple books). An attempt will be made to try to grab all the books, which are listed for sale at the URL.
To make it simple, only single page data will be scraped data and leave perform an exercise task by crawling and pagination of more pages. We will create an example of a scraper step by step as below:
Pre-requisite
Before looking further, let’s make sure to make the PHP environment ready for scraper:
- Setting up a working Web Server with PHP 7.2+.
- Composer configured.
- Understanding of XPath Selectors.
Composer is important as it allows you to install any plugin, but if you don’t have a composer you can visit the link
https://getcomposer.org/doc/00-intro.md#installation-linux-unix-macos
You can install composer locally — on a per-project basis or globally — available for all projects in your system.
We’ll be using XPath selectors to read DOM Elements and read the data we require. If you don’t know the working of XPath Selectors work, you may visit this link:
https://www.w3schools.com/xml/xpath_intro.asp
We will begin the project by creating a folder in the webserver path — named scraper and making composer available within the project folder.
Step 1: Setup Guzzle HTTP library
We need to read the HTML content of the web page using an HTTP client that can send a get or post request to the webpage URL and receive the HTML response. There are several HTTP clients available out of which we will be using the Guzzle HTTP client.
The composer is used to set up the Guzzle HTTP client. All you need to do is add Guzzle as a dependency with the help of the composer.
$ composer require guzzlehttp/guzzle
Step 2: Create the Scraper Structure
Add a new file named index.php in the project folder with the code mentioned below:
<?php
require 'vendor/autoload.php';
use GuzzleHttp\Client;
class BooksScraper {
function __construct() {
//setup base_uri
$this->base_uri = 'https://books.toscrape.com/';
// create Guzzle HTTP client
$this->client = new Client([
'base_uri' => $this->base_uri,
'timeout' => 300.0,
]);
}
function run() {
$this->load_html(); // Load HTML from URL
$this->load_dom(); // Load HTML to DOMDocument & DOMXpath to start reading nodes
$this->scrape(); // Scrape data from nodes as required
}
}
$scraper = new BooksScraper();
$scraper->run();
echo 'Success!';
?>
It is not the final code; however, it is the structure that will be used for the scraper. Let’s understand what is going on with the code:
- The first two lines designate the composer’s autoload file and are called the Guzzle HTTP library.
- A Class is created named — BooksScraper with constructor and run() function.
- Constructor function sets a base_uri variable with webpage URL and a Guzzle client variable with base_uri and max 5 minutes timeout.
- run() function performs three tasks — load HTML from a webpage, then convert the HTML to parsable DOM components, and scrape content from DOM nodes.
- In the last three lines, the Scraper is executed and the output message “Success!” is displayed.
Moving onto further steps, a code for each private function called inside run() will be added.
Step3: Writing the Function body
Adding body for each private function defined inside run() function, starting with load_html() as shown below:
private function load_html() {
$response = $this->client->get('/');
$this->html = $response->getBody()->getContents();
}
The above two lines regarding the load_html() body makes a call to the URL and respond to the HTML code of that page.
Now, we will load the HTML to DOMDocument and convert it into a DOMX path. This will allow us to read data using the XPath expressions from the page.
The structure for load_dom() is :
private function load_dom() {
// throw Exception if no HTML content.
if ( !$this->html ) { throw new Exception('No HTML content.'); }
$this->doc = new DOMDocument;
@$this->doc->loadHTML($this->html);
$this->xpath = new DOMXpath($this->doc);
}
In the first line, we have added content to load DOM, and also made sure to check to the scraper throws an exception and stops if there is no HTML content returned from the HTTP client. In case of a network failure, it helps to check the hidden bug.
Adding Scrape () function body:
<?php
...
private function scrape() {
// Identify all book nodes
$elements = $this->xpath->query("//ol[@class='row']//li//article");
if ($elements->length == 0) {
throw new Exception('Elements not present for scraping.');
}
// Loop through each book node and find book data,
// then store data to $data array
$data = array ();
foreach ($elements as $key => $element) {
$item = $this->parse_node( $element );
array_push ( $data, $item );
}
// Write $data to csv
$this->to_csv($data);
}
The scrape () function performs three main tasks
- Finding all elements holding books data on the page using XPath query expression,
- Looping through each element and finding the book data.
- Then write all the book data into a CSV file.
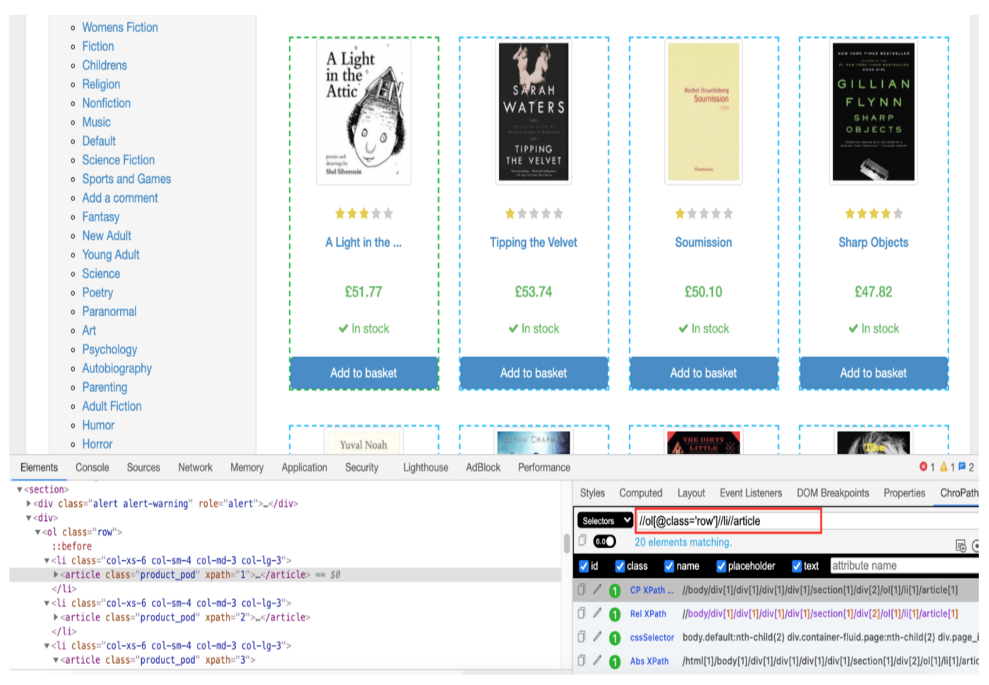
How to get XPath query expression?
At the line 3 of scrape () function following code is used:
$elements = $this->xpath->query(“//ol[@class=’row’]//li//article”);
The value inside the query function ie. //ol[@class=’row’]//li//article, is an XPath expression to get elements that contain all books. To find the XPath expression, open the page in Google Chrome. Inspect the HTML code with Developer Tools, the books are organized inside an ordered list — <ol> tag with class “row”. Within each list item, they are called in the <article> tag.
A chrome extension called ChroPath is used to validate the correct XPath expression. ChroPath helps us to generate as well as validate XPath expressions, as shown below:
Then, within the scrape () function, two more private functions are used namely — parse_node() and to_csv().
- parse_node() function takes each element node and search data for each book
- to_csv() function gets collected data items and writes to a .csv file
Step 4: Add Supporting functions
Parse_node () function body looks like as mentioned below:
private function parse_node($element) {
$item = array ();
$item['image_path'] = $this->base_uri . $this->extract(".//div[@class='image_container']//a//img/@src", $element);
$item['title'] = $this->extract(".//h3//a", $element);
$item['price'] = $this->extract(".//div[@class='product_price']//p[@class='price_color']", $element);
$item['availability'] = $this->extract(".//div[@class='product_price']//p[@class='instock availability']", $element);
$item['details_link'] = $this->base_uri . $this->extract(".//h3//a/@href", $element);
return $item;
}
In parse_node() function, an $item array variable is created. XPath expressions are used within the $element to extract book data.
For image_path and details_link, src and href attributes of corresponding elements are mentioned, while for the title, price, and availability, the text value within the element is used. The extract () helper function extracts the value based on XPath expression.
The extract () function body is mentioned as:
private function extract($node, $element) {
// Get node text
$value = $this->xpath->query($node, $element)->item(0)->nodeValue;
return trim($value);
}
Step 5: Save the Data to CSV
In the final step , to_csv() function takes $data array and saves it to result.csv file within the project folder. The to_csv() function body looks like:
private function to_csv($data) {
$file = fopen ( './result.csv', 'a' );
// write headers
fputcsv ( $file, ['image_path', 'title', 'price', 'availability', 'details_link'] );
// write books data
foreach ($data as $item) { fputcsv ( $file, $item ); }
fclose ( $file );
}
Now, run the script by opening the browser and going to the URL
http://localhost/scraper/index.php
If the script runs perfectly and displays a “success” message, then the output displayed will be as below:

While creating result.csv, keep it a point that you have the correct access right. In case you don’t have write permissions, then you will see a warning message and so the file may not be created.
Perfect work you have done, this internet site is really cool with great info .
I simply wanted to jot down a brief message so as to express gratitude to you for some of the great techniques you are writing on this website. My time-consuming internet investigation has now been rewarded with awesome content to go over with my company. I would say that most of us readers actually are truly fortunate to exist in a very good community with many awesome people with helpful hints. I feel quite blessed to have discovered the weblog and look forward to tons of more enjoyable moments reading here. Thanks again for all the details.
I am glad to be one of many visitants on this great site (:, appreciate it for posting.